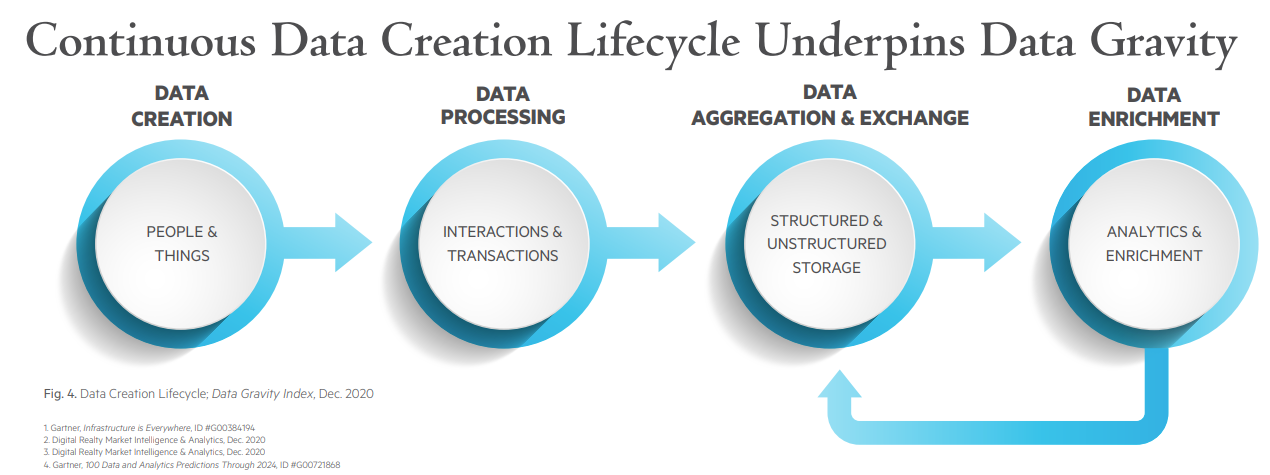
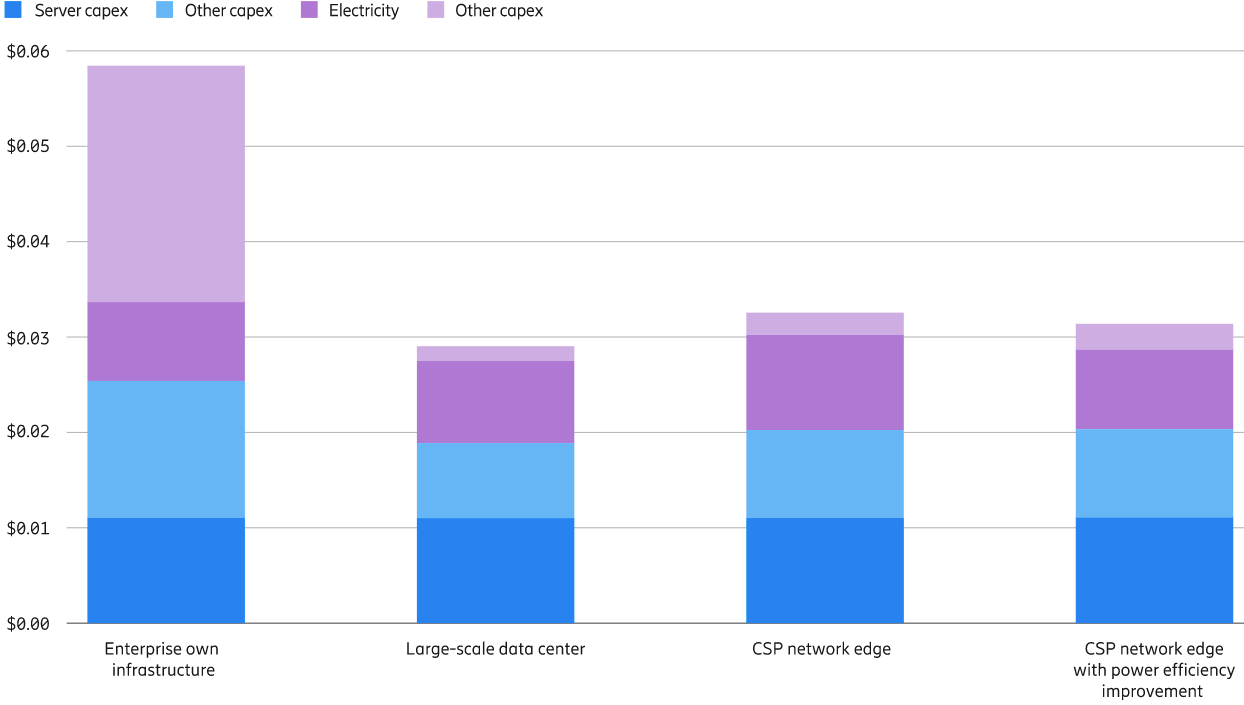
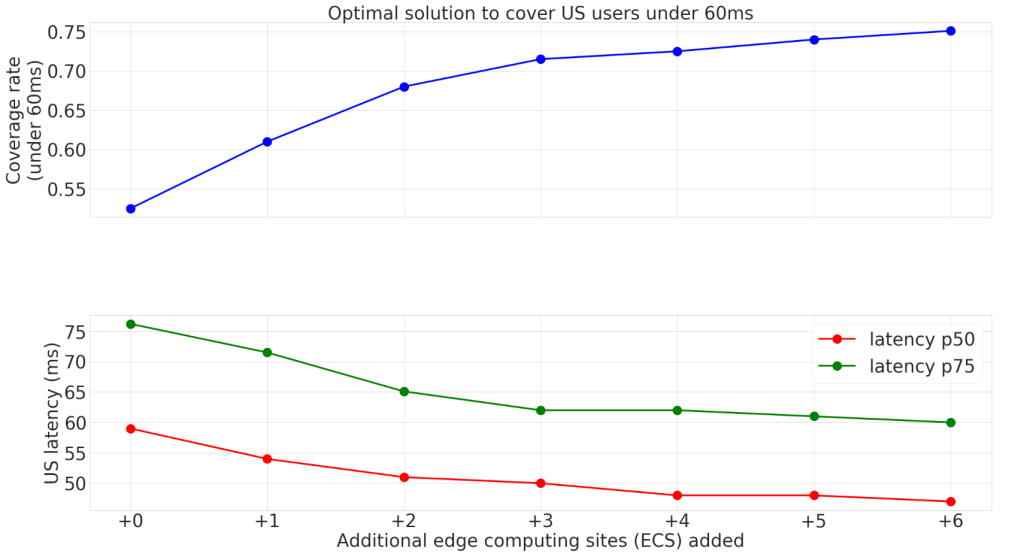
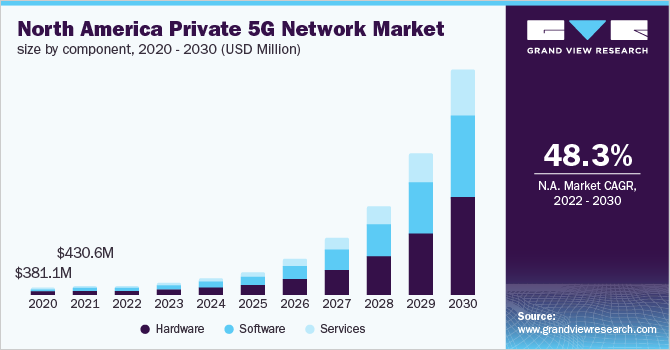
Data gravity sometimes is defined as the ability of a mass of existing data to attract more data, services and applications. The idea is that as datasets become massive, they are harder to move, and then also attract other apps, services and data that benefit from proximity to the critical mass of existing data.
Think of the notions of ecosystem, economies of scale or ability to add scope. In other realms of life, data gravity is akin to the reasons businesses and people tend to cluster in cities; why amenities and specialities flourish in cities; why ecosystem partners locate near other partners.
Perhaps data gravity is an example of the big getting bigger as more processing and storage happens at a relatively small number of global locations, driven by a shift of enterprise computing from owned facilities to use of cloud services.
Paradoxically, data gravity might grow, even as some forms of processing become more decentralized.

The reason is that data analytics are more likely to happen at remote and centralized facilities, even if real-time telemetry and process control shifts to edge facilities. For a growing range of applications reliant on artificial intelligence and real-time process control with huge data sets, processing must be at the edge.
The need for ultra-low latency will drive processing at the edge, essentially counteracting data gravity that happens for other reasons.