Data gravity is the observation that data and applications are attracted to each other, perhaps in the same way that population, economic activity and firms tend to cluster in a small number of metro areas.
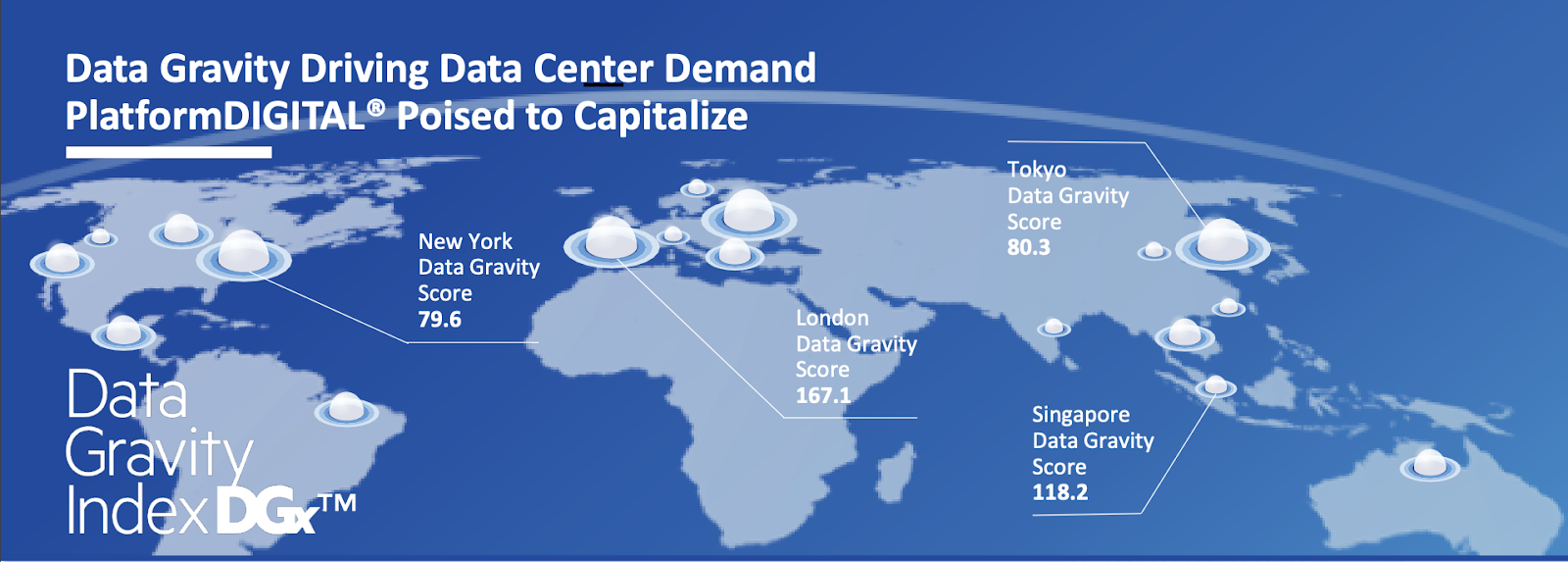
One explanation for why data gravity exists is that extremely large data sets tend to attract applications intended to glean insights from that data.
Another reason is that colocation of many servers used by many entities reduces latency and therefore improves performance, while also minimizing wide area network costs and bandwidth. That also causes a clustering of apps, data and firms in a single physical location.
In one sense, edge computing is an effort to counter data gravity, processing at the edge without storing or processing much data in centralized locations.
No comments:
Post a Comment